GraphQL Security Part I: Preventing 'traversal attacks' in your GraphQL API
GraphQL APIs need authorization rules that prevent traversal attacks and granular rules to determine if a Viewer has access to a field.


TL;DR: GraphQL APIs need authorization rules that prevent traversal attacks and granular rules to determine if a Viewer has access to a field.
This is a three part series on security concerns in scaling a GraphQL API. The planned posts:
- This post. Preventing traversal attacks from consumers composing queries that results in privilege escalation.
- Best practices to limit the the surface area of your GraphQL API.
- Safeguarding production: Complexity attacks and performance monitoring.
GraphQL is a nascent technology so most adopters have some flavor of REST as a comparative reference. One might consider REST endpoints as edges of a system, allowing limited data access from the outside via contextual actions. GraphQL inverts this by allowing the consumer to compose their data needs. By default, consumers are able to introspect the schema to see all possible actions and data structures of the whole schema.
The official guide doesn't say much on Authorization. There are a lot of great articles on the implementation of authorization logic, illustrating extension points and code patterns. When I was trying to convince my company to adopt GraphQL, the harder question I had to answer was:
Can our new GraphQL API be secured as well the current REST API? At what cost?

Authorization rules takes a lot of effort to mature. Even if we had the foresight to build it as a separate layer from our REST API, can they be reused on our Graph API? What are the new differences and challenges of authorization in GraphQL?
I recently had the chance to work on GraphQL authorization in the medical domain with strict and granular data access policies. In this post, I hope to highlight the challenge of preventing traversal privilege escalation attacks. I'll also try to detail some solutions conceptually.
I hope you find this useful! 😀☕️
Policy based Authorization: Can user X do action Y on subject Z?
I'm going to policy based authorization is a common paradigm in modern APIs. I'll use this paradigm throughout the article. On top of that, the code examples will be Ruby on Rails based on the lightweight authorization library, pundit.
You might see the word pundit appear a few more times, but the examples will be about generic policy authorization. I will do my best to make them clear for non Ruby developers too.
In a policy, there's 3 main elements. For example:
ProfilePolicy.new(user, profile).read?
From the signature above, the elements are the user, the profile and the contextual action. This answers the question:
Can the subject (user) carry out an action (read) on the domain (profile)?
The domain is usually an object but it's not a restriction. Policies are usually applied to REST semantics e.g. in an API endpoint (/api/profiles/3), the user is the session user, the domain is the CustomerProfile with ID 3 and the implicit action is the RESTful action (#show for a Rails controller).
Aside: Having principles matter...
In my opinion, the most valuable thing a company can do is to define a set of core guiding principles around data access in plain English. An example set:
- A customer has access to his own data and that of family account members who are minors.
- Any internal parties (e.g. call center agent) can only view this data with permission from the customer.
- Personal identifying information (PII) should not be exposed to any third party.
Principles like this really helps developers understand the implication of exposing data in APIs, before getting into nuts and bolts of specific domain objects.
A Primer: Thinking in Graphs, not Endpoints
TL;DR - Exposing the right graph structure that scopes data to a user avoids a lot ownership based authorization checks. But there be dragons... (next section)
REST is resource based. For a clearly defined domain, we can get really close to the academic ideal of exposing one endpoint per resource. In terms of authorization, so we are frequently answering questions like:
- Can the user access Customer with ID 3 and ProductOrder ID 6?
- What is the scope to limit the types of ProductOrder a Customer sees?
If we ported our endpoints from REST, we might end up with the query shape below.
query($customerID: ID!) {
customer(id: $customerID) {
name
email
}
productOrders(id: $customerID, entityType: CUSTOMER, status: OPEN) {
orderedAt
totalPrice
}
}
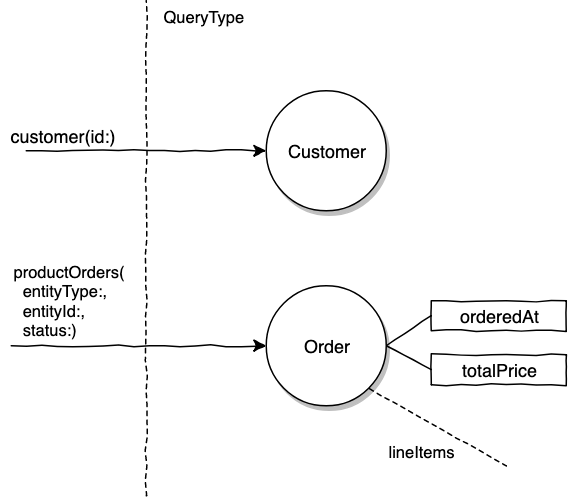
In the example above the productOrders query entry point's authorization is more involved because the entry point is very generic. It requires checking if the viewer has access to the entity who owns the order, scoping Orders and possibly a scope because of the status.
If we continued down this road, the schema will end up with a wide breadth of shallow entry points instead of a deeply connected graph. As a direct result, the API consumer might need to massage data together to build the UI tree. We might also require more roundtrips as the parameters required for a second query can only be obtained from making the first query. This is kind of like doing "REST in GraphQL". How about this?
query($customerId: ID!) {
customer(id: $customerId) {
name
email
openProductOrders {
orderedAt
totalPrice
lineItems {...}
}
}
}
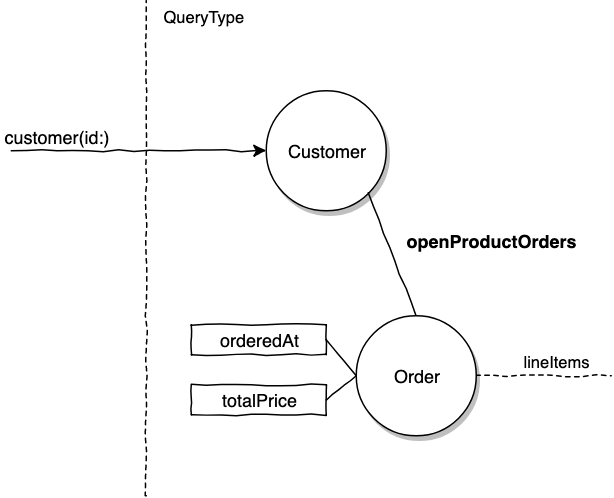
Ownership authorization checks can be avoided this way since these orders belong to the Customer, it's now a data relationship concern.
Modeling resource owners (typically a user) who has ownership of resources (products, reviews etc) is a very common pattern in GraphQL that lends itself to building great APIs for web or mobile applications. This can be close to airtight if the user is the only person who can access their own data because you don't have to worry about access delegation. For example this entry point prevents access from any other view.
currentCustomer { # The current user is a customer
name
avatarURL
openProductOrders {
orderedAt
totalPrice
lineItems { ... }
}
}
But I digress. I'm going to stop here on modeling GraphQL APIs. It's really a topic on its own that I'm not doing justice with oversimplified examples.
The Plot Thickens...
All is well and good. One day, you get a bug report from a seller that all his new campaign discount codes were used up. None of the codes have been disclosed to the public yet!
A sinking pall sets over you. Just as suspected, it is something related to the new GraphQL API. You notice a customer making an unusual number of calls to the Graph API. It's obvious because the new API is only used a few times in the application's life cycle.
Well, new problem, since GraphQL uses a single POST endpoint and it's typical not to log POST bodies, there's no visibility to the queries ran. This makes it really hard to debug. If it's not obvious enough, this is a hint to think about your GraphQL logging setup 😏. (Shameless plug: Covered in Part 3)
By sheer luck, this customer is currently running queries, so you race over to DevOps to turn on full logging.
# Root cause: We found a very abnormal query crafted by a customer
query getCustomerData($customerID: ID!) {
customer(id: $customerID) {
openProductOrders {
orderedAt
totalPrice
seller {
name
activeCampaigns { # Added by the 'enterprising' customer
discount # Discount percentage on order
code # unique code for discount
}
}
}
}
}
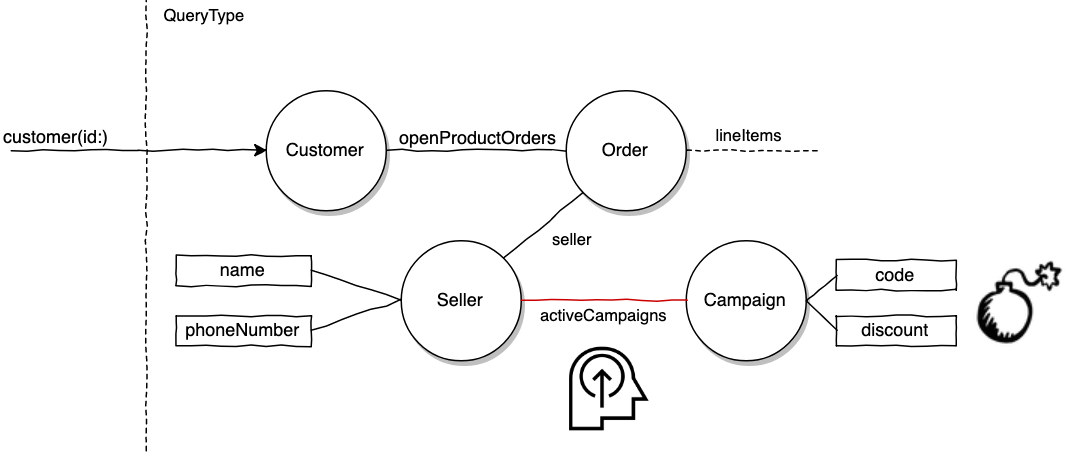
D'oh! This is what happened:
- You built out the customer graph and made sure the overall graph is secure.
- Someone on your team exposed the
SellerTypeto casually expose the seller's name for some internal reporting use. That was an easy PR to approve. 😏 - Another team working on merchants decided to adopt GraphQL. They were so happy to find there's existing
SellerTypeplumbing. They added fields, such asactiveCampaigns, for a 2.0 version of the Merchant app's Campaigns UI. - Our enterprising customer ran the Introspection Query on the Graph endpoint to visualize the schema. He realized it was straightforward to request for campaign fields. Thank you, nicely annotated schema.
Thankfully the customer in question was only looking for bargains. 😅
This cautionary tale highlights the traversal privilege escalation attack. By the way, I made up this term. There is a natural openness in GraphQL APIs since the consumer does query composition with support from first class introspection capabilities. We really have to think about authorization in terms of securing all potential traversal paths. It's important to have the authorization implementation thought out earlier as the number of connections between nodes grow at an accelerating pace as the adoption reaches critical mass.
That might sound like an impossible task in theory but there are ways to deal with this in practice. One very important measure is to disallow unprivileged users from making queries, commonly referred to as persisted queries, that will be discussed in part 2.
GraphQL Authorization in Practice
In a REST API, authorization code might look like this:
# Somewhere in a controller
def show
customer = Customer.find(customer_id)
# renders 403 forbidden if policy returns false
unauthorized unless CustomerPolicy.new(current_user, customer).show?
render json: customer, serializer: CustomerShowSerializer
end
# The naive policy class
class CustomerPolicy
def show?
return user.is?(customer)
end
end
The question we answered is:
Can the user access this endpoint?
Usually these policies are gatekeepers, once it passes, it no longer has a hand in the rest of the execution of the code. I like to analogize this setup as a bar with a bouncer who checks your ID at the door but places no additional safety/security in the venue :).
If we ported this analog to GraphQL, we might implement this rough cut in the query root resolver.
class QueryType
# Field definition
field :customer, CustomerType, 'Finds a customer by ID' do
argument :id, ID, "Customer's UUID", required: true
end
def customer(id:) # Resolver function
customer = Customer.find(id)
raise_unauthorized_error unless CustomerPolicy.new(context[:current_user], customer).show?
return customer
end
end
As the "enterprising" customer has shown us, this is not good enough. In REST, we choose which attributes to serialize in an endpoint. For GraphQL, the data selection is done by the consumer. The parallel question we have to answer is:
Can the user make a certain field selection in the schema?
In Ruby's GraphQL implementation, I found some ways of integrating policies via Pundit.
- graphql-pro: Pundit integration part of the paid library by the author of GraphQL Ruby. I'm use this library at work.
- graphql-pundit: A library for pundit integration.
- graphql-guard: A more generic integration that's not restricted to pundit.
All the libraries above offer DSL helpers that remove glue code required to invoke the right policy at the field level. This allows you to run a policy before a field is resolved.
# Field level authorization example from graphql-pundit
class CustomerType
field :name, String, 'First + Last', authorize: true
# authorize: true calls CustomerPolicy's name? method
end
Doing authorization at the field level is extremely granular. GraphQL Pro offers an Object Integration that runs a policy right after loading an object but before resolving field selections. How it works in the example below.
class SellerType < BaseObject
pundit_role :read # Object integration
# Runs a policy check right before
# resolving fields on an object
field :name, ...
end
This invokes policies by convention when a query makes any selection on the seller type
SellerPolicy.new(viewer, seller).read?
Now we can secure traversal by defining object access policies. In this case, the seller's read? policy might be naively defined as:
def read?
# Let's say seller object access is limited to themselves
viewer == seller
endAuthorization is usually implemented in additive layers. Object policies are great for applying ground rules for accessing a domain.
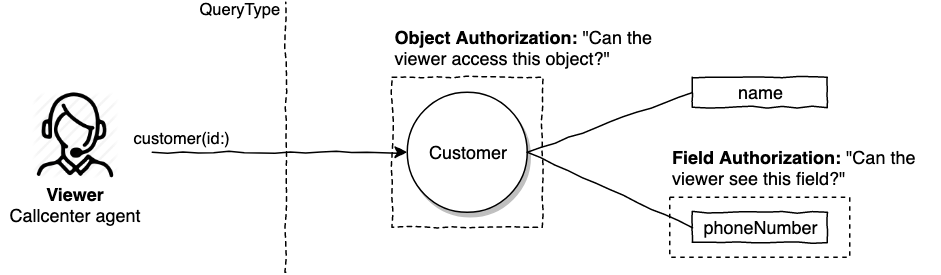
Wait wait. What about the use case we had right here to show the product seller's name? This policy is going to prevent the customer accessing the seller's name because customers have no access to seller objects.
The exact solution really depends on your domain. In my own experience, a domain object, like a row in a sellers table with an ORM model Seller, can be expressed by multiple GraphQL types. Our solution might be to represent common display fields of a seller via a SellerProfile type.
type SellerProfile {
"""
Seller display fields that are deemed safe to display publicly
"""
name: String!
shopName: String!
tagLine: String!
}
Our enterprising customer example will look like this now.
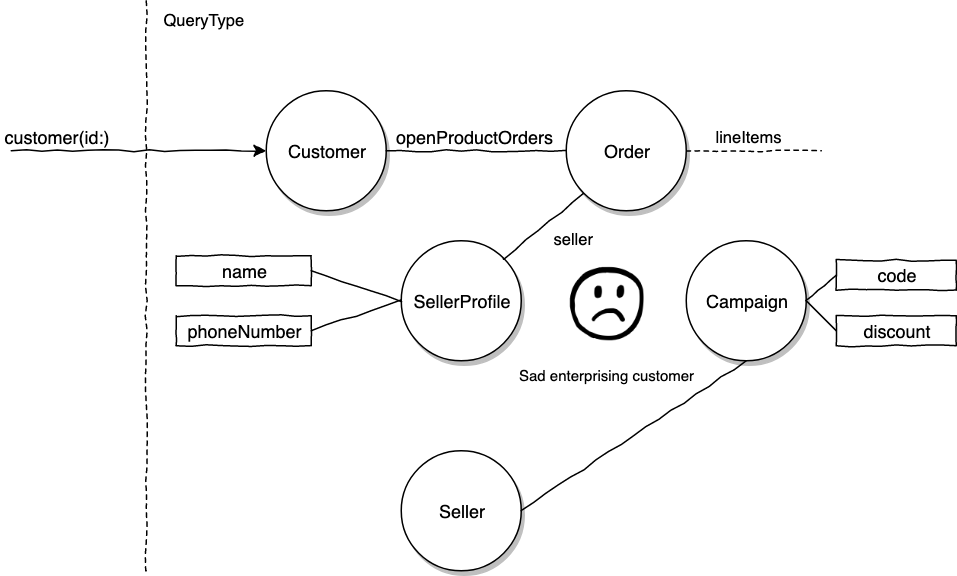
The impression I hope to leave is the design of our schema will have bearings on the difficulties of authorization. Think domain design, but also think about how the schema might be traversed by the various different viewers in your domain.
Rule of thumb: Resource owners and resources
We can generalize the situation so far to a case of traversing between resource owners (seller, customer) to resources (orders, campaigns).
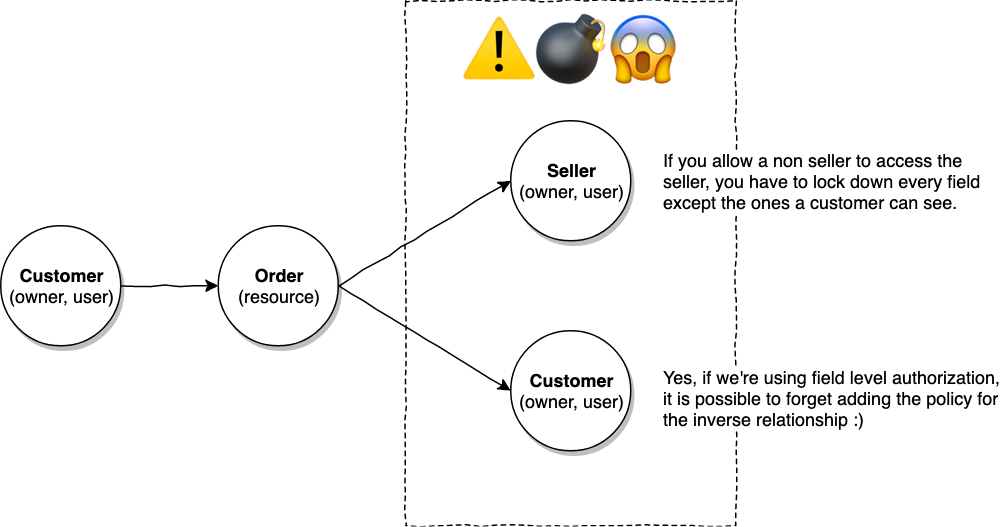
It's typical to have a relationship from an owner to a resource. However, every time traversal is done from a resource to an owner, we have to meticulously consider the extra depth opened up by these relationships.
Most web and mobile UIs are essentially tree structures starting off with the user at the the top of the tree. It's a good strategy to always expose shallow types such as the SellerProfile when we're just getting display fields. We can always expose the full Seller when it's needed.
Can the Viewer with "object" access see all fields?
There are usually some attributes that sit on a table that does not belong to the domain they represent. For example, your user object might have attributes like failed_logins_count and customer_service_priority_level that we most probably don’t ever want to show the user. The easiest solution: Don’t expose these fields.
These fields are directly related to the user but not owned by them. If your e-commerce app have a concept of customer service agents, they might need to see these fields. For data that lives on a table/model that doesn't belong to the same domain, I think the clear approach is to expose them in a different connected type, ala SellerProfile above, this makes it much easier to lock down using the object access paradigm.
Now for the more insidious problem of access delegation. let’s say a customer has access to another customer as part of a family plan.
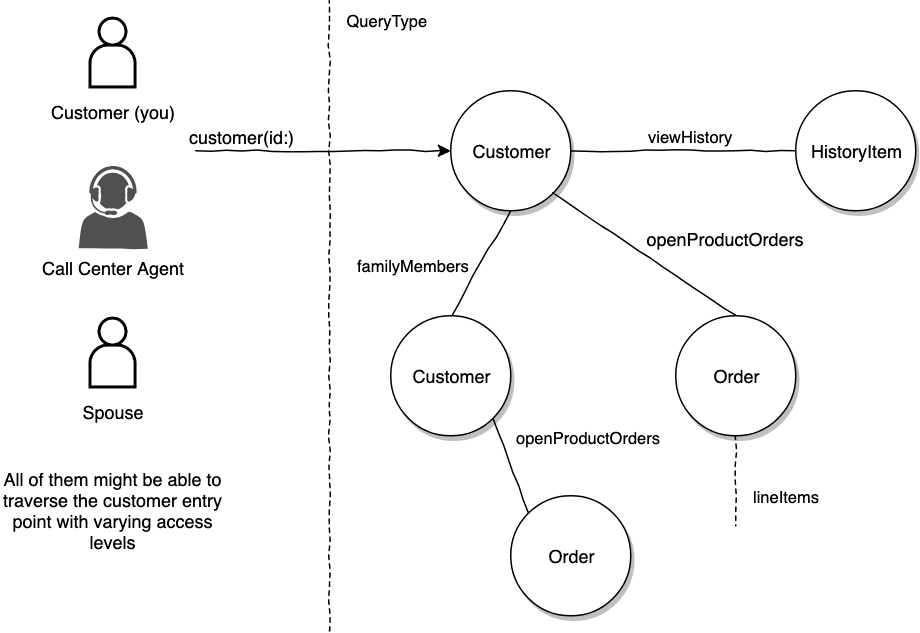
So in terms of object access, yes, my spouse can access my customer record. She also has the ability to see most of the basic customer record fields. Yet she should not have the ability to view fields such as my recently viewed products. (Disclaimer to spouse: "My only inspiration for this example is because I wanted to buy you a birthday surprise").
# It's a world of difference between the two types of entry points
query($customerID: ID!) {
currentUserCustomer {
# No delegation worries here
id
name
# ...
}
customer(id: $customerID) {
# Do different user types have different access levels?
id
name
# ...
}
}If your domain only requires currentUserCustomer type of access, this eliminates the problem of delegated access. Delegated access is a very real world use case which eventually finds it way to sneak into every app. Impersonation is one clear way to model this. You bequeath the rights to the agent temporarily to view all your information. That is easy to model but becoming less acceptable in the age where society is finally taking privacy more seriously.
We can also consider making a separate schema just for admins. Since we're accessing the same domain objects, we have to define a whole new set of types that have less fields. This avoids authorization by duplicating the domain objects. The cost benefits of this will really depend on the context. Personally, I found this to be unscaleable.
Deep in our hearts we know that we will need to use field level authorization where individual fields are guarded by policies.
The field declaration:
field :history, [HistoryItem]!, “customer’s view history”, pundit_role: :view_history
The invoked policy:
CustomerPolicy.new(viewer, customer).view_history?
Wow, this is serious pain. I work in the medical domain where this is necessary and important to make sure the API never leaks any unnecessary patient data. I thought this was going to be a nightmare for other developers, having to write policies per field.
After implementing some of them, I realized there are silver linings. Most of the time, the question boils down to two main types of access:
- Does a privileged third party Viewer (e.g. call center agent, admin user, developer) have the right to see a field?
- Does a domain user (e.g. spouse, member of organization) have access to a certain field owned by a parent object? (e.g. organization)
Since that's only dependent the user type, we can add helpers to make things easier to maintain. For example:
class CustomerType
field :name, String, 'Full name', view_allowed: :all
field :openOrders, [OrderItem]!, view_allowed: [:agent, :self_and_related, :admin]
field :history, [HistoryItem]!, “Recently viewed products”, view_allowed: :self
end
As the holy grail, I'm hoping the core principles on data access can move my company away from role based authorization.
# The holy grail. 🏆
field :name, String, 'Full name', categories: [:personal_info]
field :history, [HistoryItem]!, “Recently viewed products”, categories: [:personal_private]
It might look like we're just renaming the roles, but semantically this is modeling access closer to our business domain.
But what about performance...
All this work has to be done when returning a selection, how is the performance? Every language is different but we know I/O and networking costs are the significant common factor.
So far it's not really a problem yet because of two assumptions that are held:
- Object access policies mostly require
[viewer, object]which does not involve extra I/O to load objects. Authorization runs right after resolving object, which is required to fulfill the query anyway. - Field policies usually only check
Viewertype which doesn't require any additional loading.
Think about your domain, what might cause network, I/O or heavy computation (in order of pain) when doing authorization?
Does REST not have this problem?
Securing a GraphQL API seems so much harder, but I'd argue that REST APIs have parallels of the same problems manifesting in other ways 😆.
Let's bring in a typical REST controller action
class CustomerController
def show
authorize @customer, :show # Can current user access /customer/:id?
# We passed the policy 👆, but how is the serializer guarded?
render json: CustomerSerializer.new(@customer).to_json
end
end
We can get away with not writing authorization logic for the serializers by assuming that developers (and the review process) will ensure the serialization layer does not expose data that cannot be accessed by the caller.
Yet, when a small PR is submitted to add a field to the serializer, the code usually does not lead the reviewer to think about authorization. It's also really hard to know how the view serializer is used in different contexts.
If you're in a domain that really cares about locking down data access, GraphQL is your friend both in that field selections are exact and authorization has to be explicitly implemented at the field level.
The attack surface area can be reduced
We should do our best to implement authorization correctness but be cognizant that it will never be perfect. There are several ways to retain the developer ergonomics of using GraphQL while reducing the surface area in production.
Part 2 is these practices (such as limiting visibility, persisted queries).It will be linked here once it's ready.
With that, I'd like to conclude the post. Thanks for reading this and I'll appreciate any feedback. Feel free to provide feedback or discuss this on Twitter.